Scraping a password protected webpage in Alteryx with cURL
Imagine you need to download all the invoices from a supplier’s website which is password protected. Also, the page with the invoice links sits behind a login page, which makes the setup in Alteryx a bit more tricky. In this post I am going to demonstrate how to scrape the data from a password protected webpage with cURL in Alteryx.
As an example I will be using the TFL portal of open data feeds. The first page is a login page where we input login and password details.
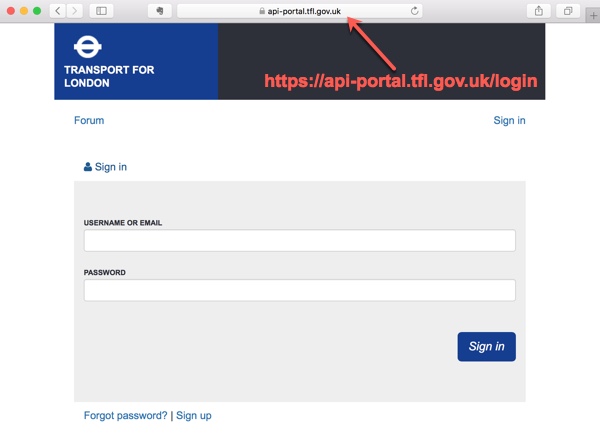 After clicking the ’Sign-In’ button we are redirected to the webpage with all the links to multiple data feeds and APIs.
After clicking the ’Sign-In’ button we are redirected to the webpage with all the links to multiple data feeds and APIs.
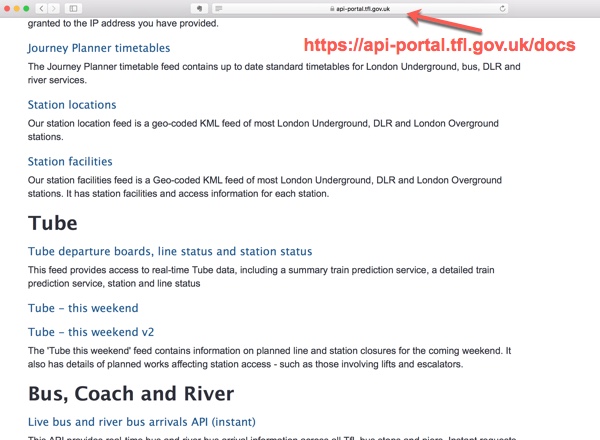
Because user authentication happens on one page and we want to scrape another page, we can’t use the standard download tool in Alteryx. Instead we are going to run a simple cURL script in the Run Command tool.
Why use cURL and Alteryx?
First of all, why do we need to use cURL instead of the Download tool in Alteryx? Because it is more flexible. While the Download tool is easy to use and supports multiple authentication protocols, I am not aware of an easy way to use it to fill in web forms or send chained requests to multiple webpages. While cURL makes this easy for my scenario. cURL “is designed to transfer data with URLs”, it is portable, powerful, open-source and free. There is also a lot of documentation about how to use it.
Then why do we need to add Alteryx? Adding Alteryx on top of the cURL script can make our life easier. A single line of cURL code can be packaged in a macro and used dynamically. Most importantly once we scrape or download the data we need, we can do all the data prep in the same place, and also schedule this work.
cURL script
cURL is usually pre-installed in MacOS and Linux environments, however older Windows versions will not include cURL by default. If you don’t have it I recommend getting the latest download.
The cURL script we are going to use is a fairly straightforward single command line.
curl -X POST -F username=name -F password=psw https://api-portal.tfl.gov.uk/login –next -X GET https://api-portal.tfl.gov.uk/docs -o %temp%\temp_read.csv
-X POST specifies POST method for the request which means posting data to the web page
-F username=name sends a “name” value into the form named username
-F password=psw sends a “psw” value into the form named password
Note: forms might be named differently on different websites, use developer tools in the browser to double check
–next sends the next request within one command line
-X GET second request uses GET method in order to receive the data from the webpage
-o specifies the output file
Read more about cURL command options here.
cURL in Alteryx
cURL is simply used in the Run Command tool. Since the script is very short and doesn’t change dynamically, it can be inserted in the Command Arguments field. The below workflow will create a simple text output with the HTML of the webpage.
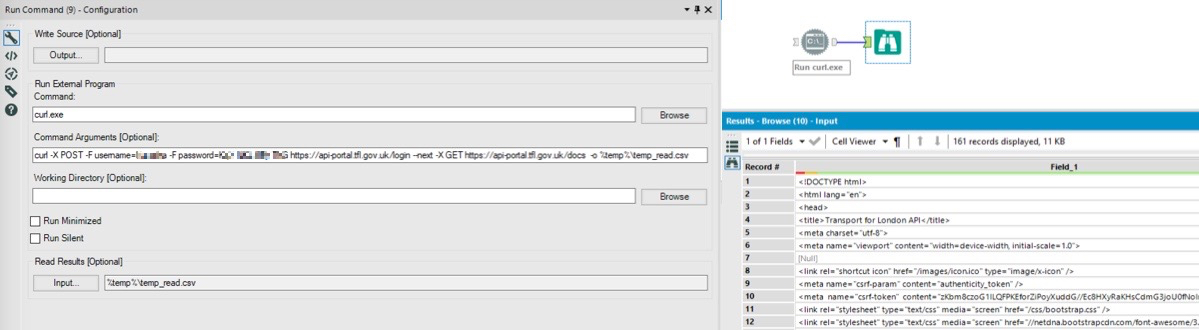
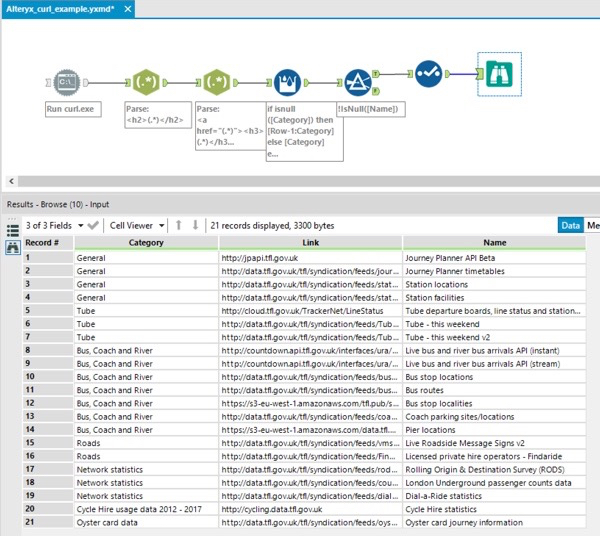
This HTML can then be parsed with RegEx to get all the direct links we need. The exact RegEx expression will depend on the webpage structure, so there is no one RegEx that will fit all.
I used two RegEx expressions. The first parsed all category headers and the second parsed links and the feed names.
- <h2>(.*)</h2>
- <a href=”(.*)”><h3>(.*)</h3></a>
Here is an example output table with all the direct links that we can use later in many ways depending on what we want to do.

Hi Natasha, Interesting post, trying to get it working but receiving a File not Found error in the Run command function.. it appears it’s not finding the temp_read.csv file.
Any ideas? Could this be a permissions issue that it’s not allowed to create the csv file, or something along those lines?
OK, just seen that running the code directly in cmd.exe works fine, it creates the temp_csv, but running it from the run command function in Alteryx it doesn’t create the file. I’m pretty sure there’s a curl error there but the cmd screen closes so quickly I can’t see what it says!